多个头文件
另一种物理组织方式是让每一个逻辑模块有自己的头文件,其中定义它所提供的功能。这样,每个 .c 文件用一个对应的 .h 文件描述它所提供的东西(它的界面)。每个 .c 文件包含它自己的 .h 文件,或许还需要包含其他 .h 文件,如果那里描述了本 .c 文件为实现自己的界面中说明的服务所需要的有关其他文件的信息。这种物理组织对应于模块的逻辑组织,为用户提供的界面放在它的 .h 文件里,为实现部分所用的界面放在另外的以 _impl.h 为后缀的文件里,而模块中的函数、变量等的定义则放在 .c 文件里。按照这种方式,分析器将表示为三个文件。分析器的用户界面由 parser.h 提供
// parser.h:
namespace Parser { // 给用户的界面
double expr(bool get);
}
为实现分析器的函数所共享的环境通过parser_impl.h提供
// parser_impl.h:
#include "parser.h"
#include "error.h"
#include "lexer.h"
namespace Parser { // 给实现的界面
double prim(bool get);
double term(bool get);
double expr(bool get);
using Lexer::get_token;
using Lexer::curr_tok;
}
将parser.h文件#inlcude进来,是为了使编辑器能检查一致性(9.3.1节)。
实现分析器的函数都存放在parser.c里,用#include指令包含Parser的函数所需要的头文件:
// parser.c
#include "parser_impl.h"
#include "table.h"
double Parser::prim(bool get) { /* ... */ }
double Parser::term(bool get) { /* ... */ }
double Parser::expr(bool get) { /* ... */ }
用图形表示,分析器和使用它的驱动程序看起来像下面这样
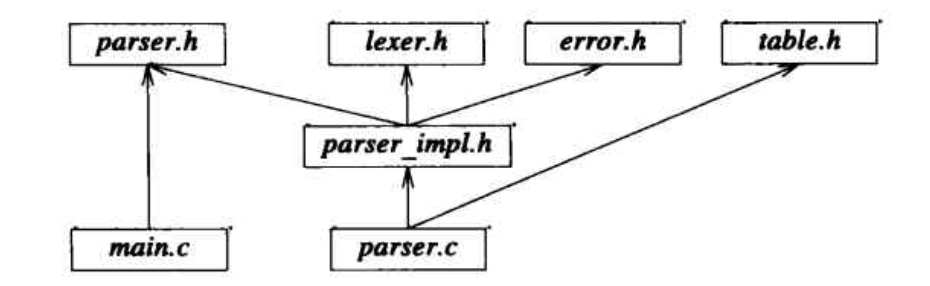
正如我们所希望的,它非常接近8.3.3节描述的逻辑结构。为了简化这个结构,我们也可以将#include table.h放入parser_impl.h而不是parser.c。无论如何,table.h是这样的一个例子,在表示分析器函数的共享环境时并不需要它,只是函数的实现需要它。事实上,只有一个函数prim()需要table.h,所以,如果我们确实需要维持最小的依赖性,那么就可以将prim()放入一个自己的 .c 文件,且只有这里写#include table.h:
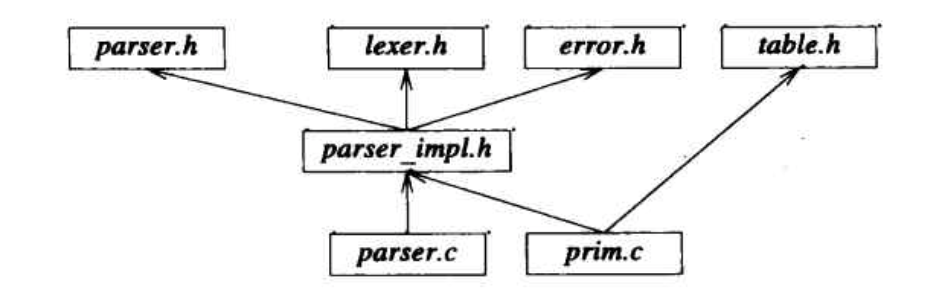
除非要处理的模块规模更大,否则就无须做这种精细加工。即使对真实模块的模块,用#include包含一些额外的只是个别函数所需要的文件也很常见。此外,存在多个 _impl.h 的情况也很常见,因为在一个模块里,不同的函数子集可能需要不同的共享环境。
请注意, _impl.h 的写法既不是标准,也不是一种通用的约定,它只不过是我所喜欢的一种命名方式。
为什么要费心于这种多个头文件的复杂模式?显然,将所有声明简单地丢进单一头文件里,费的心思要少得多,就像前面对 dc.h 所做的那样。
多头文件组织方式能够适应于比我们玩具式的分析器大几个数量级的模块,以及比我们的计算器大几个数量级的程序。采用这种组织类型的基本原因,就是它提供了我们所关心的更好的局部性。在分析和修改大程序时,对于程序员而言,最重要的东西就是能将注意力集中于相对较小的代码块。多个头文件的组织方式使人能很容易去确定分析器代码依赖于什么,可以忽略掉程序额其他部分。而单一头文件途径则会强迫我们去关注可能由某个模块使用的所有声明,设法确定它是不是与我们有关的东西。一个很简单的事实是,维护代码的工作总是根据不完全的信息和局部的视角去完成的。多个头文件的组织方式使我们能仅仅从某种局部观察点出发,“自里向外”成功地工作。单一头文件方式---就像所有其他以某种全局性的信息宝库为中心的组织一样---需要一种自上而下的工作方式,从而使我们永远弄不明白到底什么东西依赖于什么东西。
更好的局部化将能减少编译一个模块所需要的信息,从而导致更快的编译。这个影响也可能是非常显著的。我看到过这样的情况,经过简单的依赖性分析而更好地使用头文件,使编译时间减少到只有原来的十分之一。
🔚